The classification problem is different from the regression problem in that y takes a discrete value (a category label) rather than a continuous value.
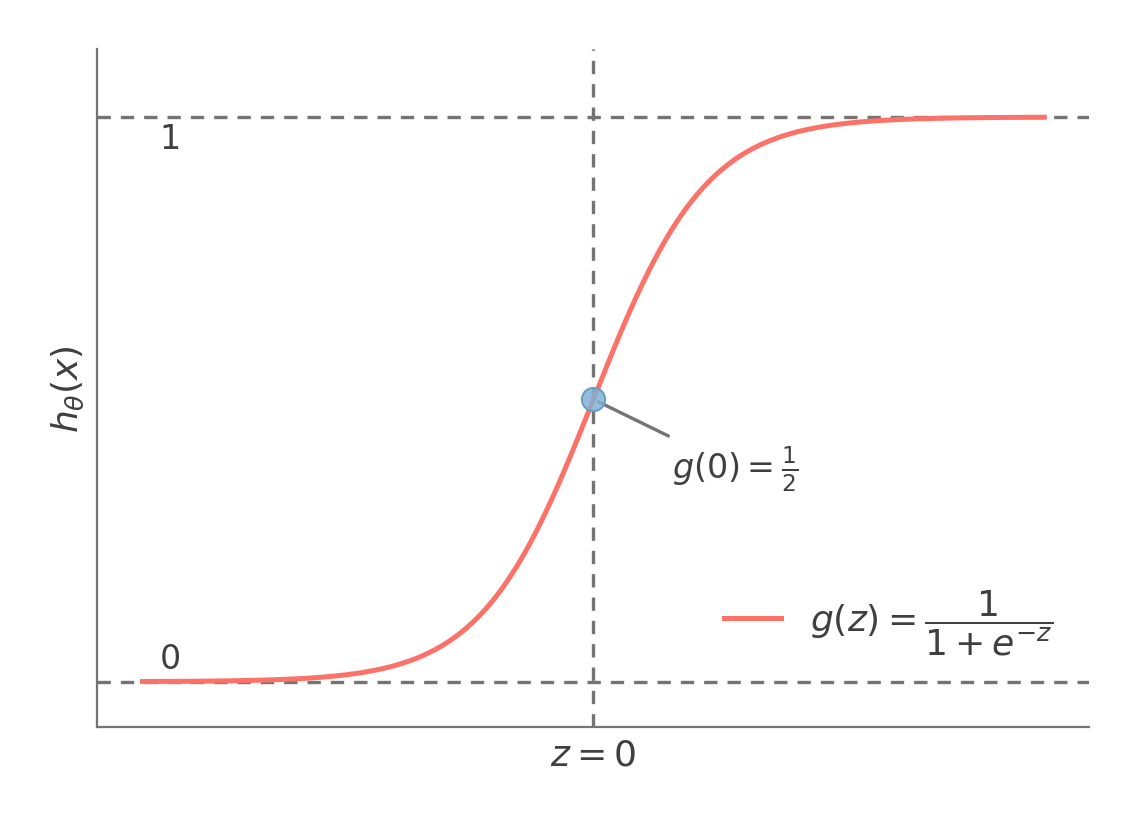
Therefore, for logistic regression, we will choose our hθ(x) to be a sigmoid function that squishes any real number to a value between 0 and 1.
hθ(x)=g(θTx)=1+e−θTx1
The sigmoid function converts the score θTx into a probability, with g(0)=21.
Let's assume that:
p(y=1;x,θ)=hθ(x)p(y=0;x,θ)=1−hθ(x)
Now this can be rewritten as:
p(y∣x,θ)=(hθ(x))y(1−hθ(x))1−y
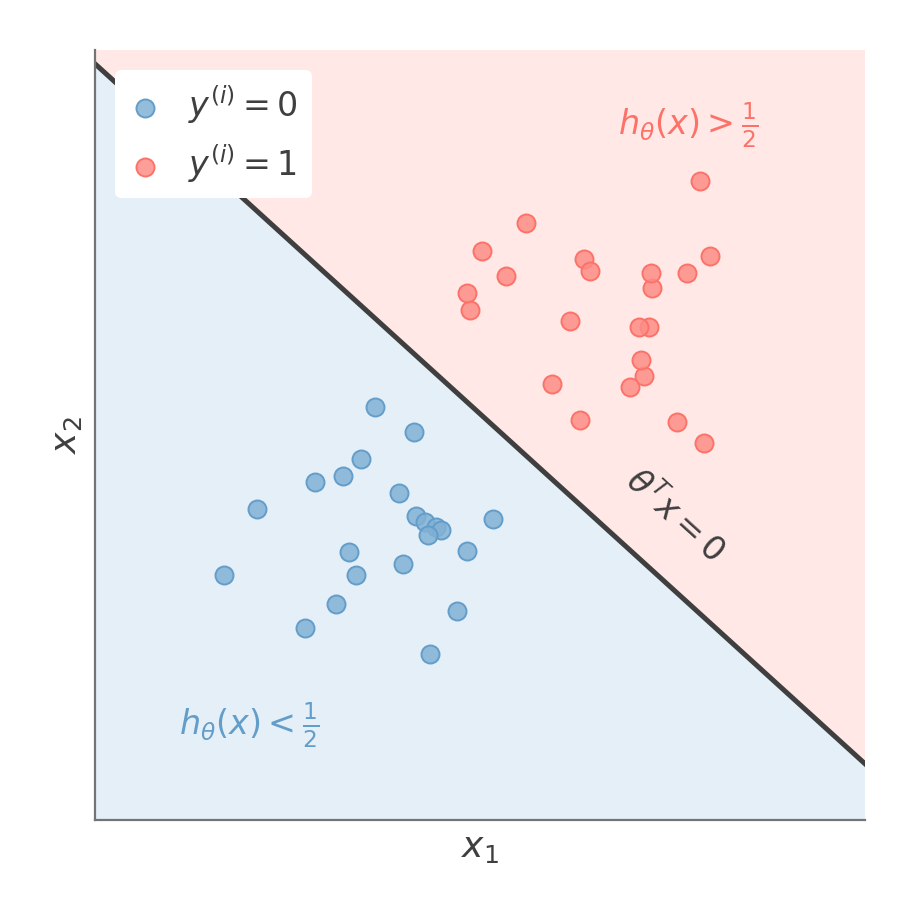
Logistic regression predicts one class on one side of the boundary θTx=0 and the other class on the opposite side.
And so our gradient descent update rule to maximize the log-likelihood becomes:
θj←θj+α(y(i)−hθ(x(i)))xj(i)
See derivation
See derivation
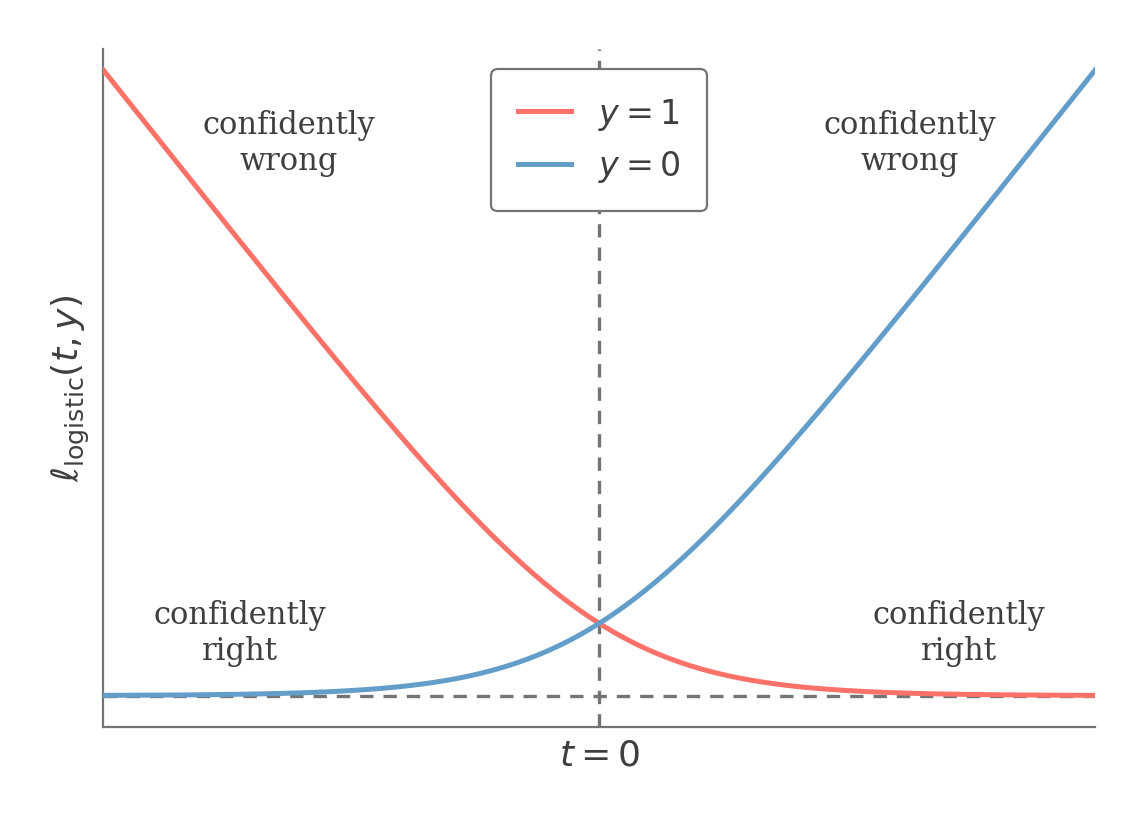
Also, note that maximizing the log-likelihood is equivalent to minimizing the logistic loss where t=θTx
argθminℓlogistic(t,y)=argθmaxℓ(θ)
Minimizing the logistic loss pushes the score t=θTx toward the correct sign: a confidently wrong prediction is penalized without bound, while a confidently correct one costs almost nothing.
See derivation
Multiclass Classification
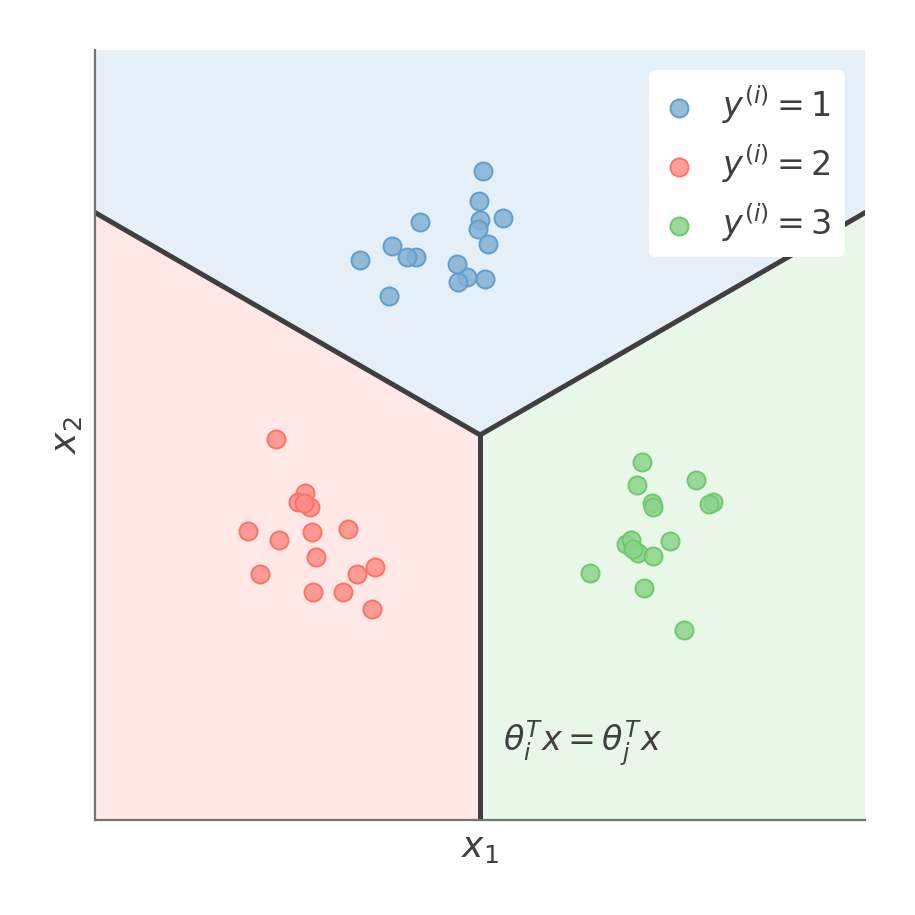
For multi-class classification, if we have k classes, we will have k∗θ parameters and will use a one-vs-all approach.
p(y=i∣x;θ)=ϕi=∑j=1kexp(θjTx)exp(θiTx)
Softmax assigns each point to the class with the largest score θiTx, carving the feature space into k regions whose boundaries lie where two classes tie.
Our cross-entropy loss (which is the negative log-likelihood) can then be written as:
Taking the derivative of the cross-entropy loss with respect to θj, we get:
∂θj∂ℓce(θ)=i=1∑m(ϕj(i)−1{y(i)=j})x(i)
Note that ϕj(i)=p(y(i)=j∣x(i);θ).
Therefore, since ϕj(i) is a probability between 0 and 1, if y(i)=j, we add a negative value of x(i) to our gradient. And if y(i)=j, we add a positive value of x(i) to our gradient.
Our gradient descent update rule is then:
θj←θj−αi=1∑m(ϕj(i)−1{y(i)=j})x(i)
See derivation
Please use a larger screen
This content is best viewed on a laptop or desktop device.