However, the above equation is not concave with respect to θ. Hence, we cannot use gradient ascent to find the maximum likelihood estimate.
Moreover, if p(x;z;θ) is an exponential family distribution, then taking the derivative of the above equation with respect to θ doesn't typically lead to a solvable expression.
To get around this, we imagine Q(z) to be some distribution over z so that ∑zQ(z)=1 and Q(z)≥0
Jensen's Inequality
Jensen's inequality states that for a convex function [f′′(x)≥0] the following inequality holds:
E[f(X)]≥f(E[X]).
And for concave functions:
E[f(X)]≤f(E[X]).
Also, if X is a constant then X=E[X] and:
E[f(X)]=f(E[X]).
Using Jensen's inequality, we can see that the following inequality holds:
Repeat until convergence {(E-step) For each i, set {Qi(z(i))←p(z(i)∣x(i);θ)}(M-step) Set {θ←argθmaxi=1∑nELBO(x(i);Qi,θ)}}
In the E step we find the estimated distributions over z(i) using our current value of θ and thus our current estimated distribution over x(i) given z(i). We do so using the Bayes' rule:
In the M step we update the value of θ to maximizes the ELBO for which it is equal to logp(x;θ) for our current values of θ.
Proof of Convergence
It can be shown that the EM algorithm converges to the maximum likelihood estimate of θ as the number of iterations goes to infinity.
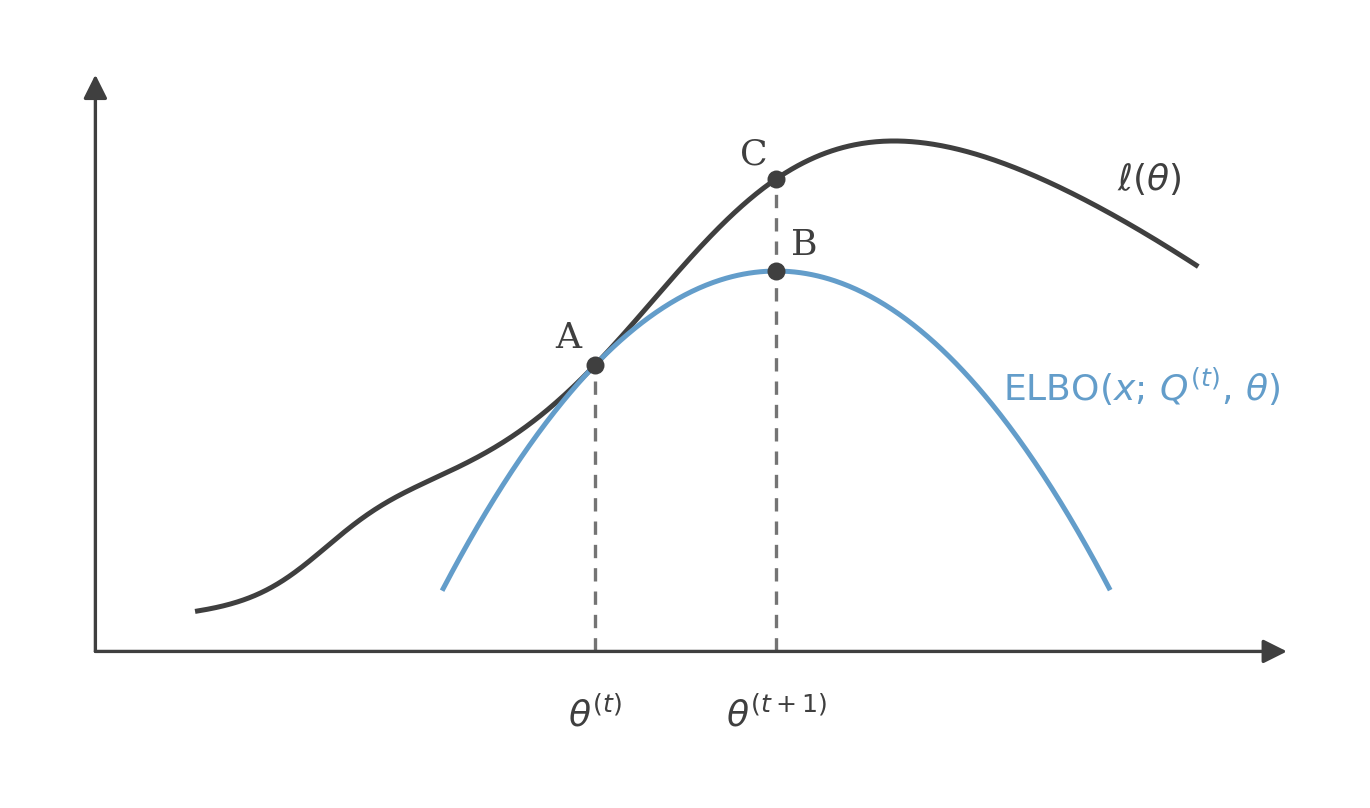
We saw that the for any given value of θ and any distribution over z, our log-likelihood ℓ(θ)=logp(x;θ) is always greater than the ELBO(x;Q,θ).
For fixed Q(t), the ELBO touches ℓ at θ(t) (A); the M-step maximizes it to θ(t+1) (B), and since ℓ≥ELBO, ℓ(θ(t+1)) (C) is higher still — so a step never decreases ℓ.
Hence,
ℓ(θ(t+1))≥i=1∑nELBO(x(i);Qi(t),θ(t+1))
Moreover, since in the M step, θ(t+1) is chosen to maximize ELBO(x;Q(t),θ(t)):
Finally, in the E step, Q(z) is chosen such that for the current value of θ, the log-likelihood and the evidence lower bound are equal.
i=1∑nELBO(x(i);Qi(t),θ(t))=ℓ(θ(t))
Putting it all together, we have the following inequality:
ℓ(θ(t+1))≥ℓ(θ(t))
Note that the reason we wanted a tight bound on our inequality was to guarantee convergence. Otherwise after the E step, our ELBO(x;Q(t),θ(t)) could have been lower than our log-likelihood ℓ(θ(t)). This would've meant that ℓ(θ(t+1)) could have been lower than ℓ(θ(t)).
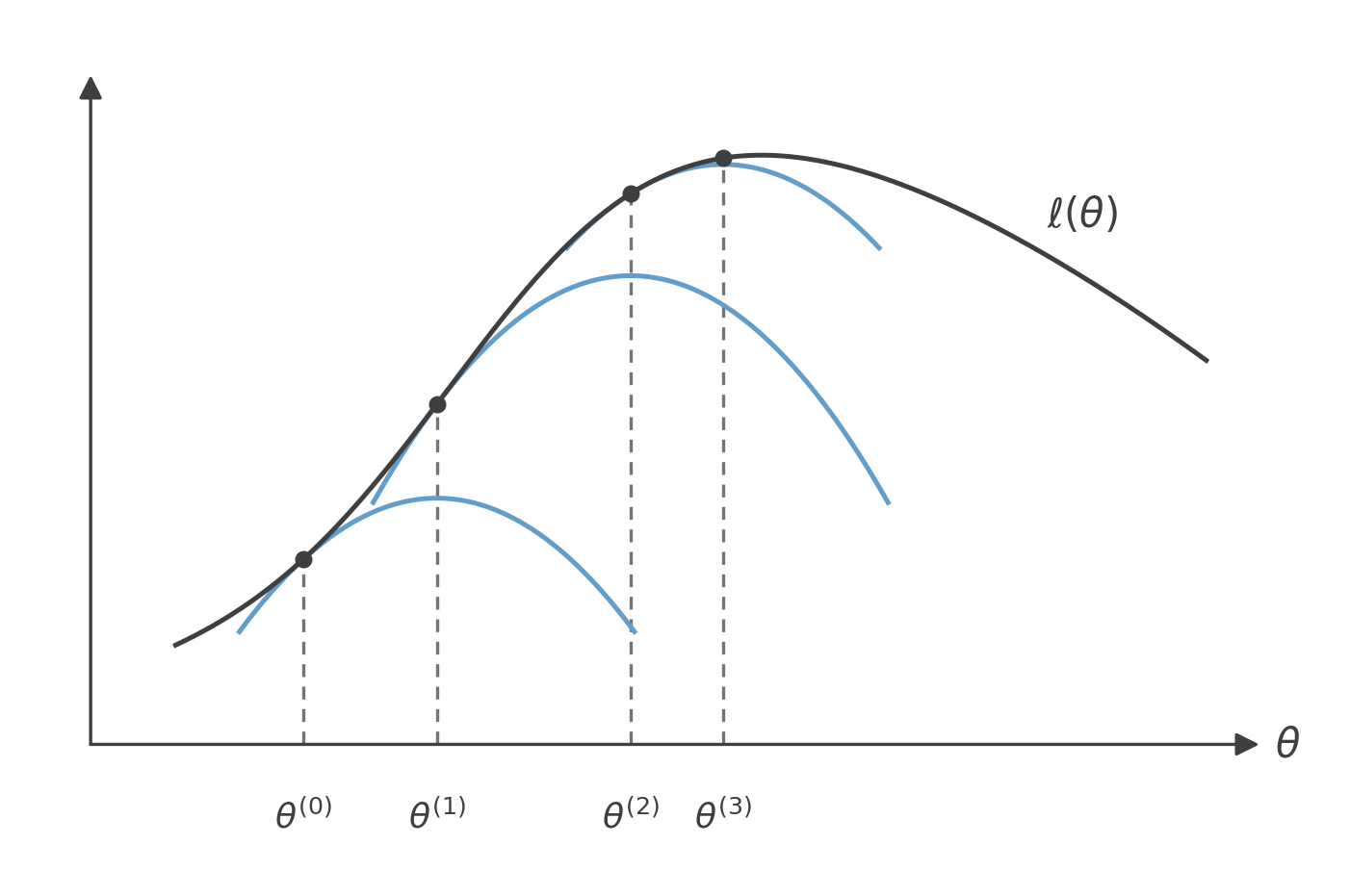
Repeating the step, each fresh bound is tangent to ℓ at the current θ(k) and is maximized to reach the next iterate; the iterates climb ℓ with shrinking steps, converging to a local maximum.
Other Interpretations
The evidence lower bound can be rewritten as:
ELBO(x;Q,θ)=Ez∼Q[logp(x∣z;θ)]−DKL(Q∥pz)
This would mean that maximizing ELBO over θ is equivalent to maximizing p(x∣z;θ) since the KL-divergence term does not depend on θ.
See derivation
Similarly, the evidence lower bound can also be rewritten as:
ELBO(x;Q,θ)=logp(x)−DKL(Q∥pz∣x)
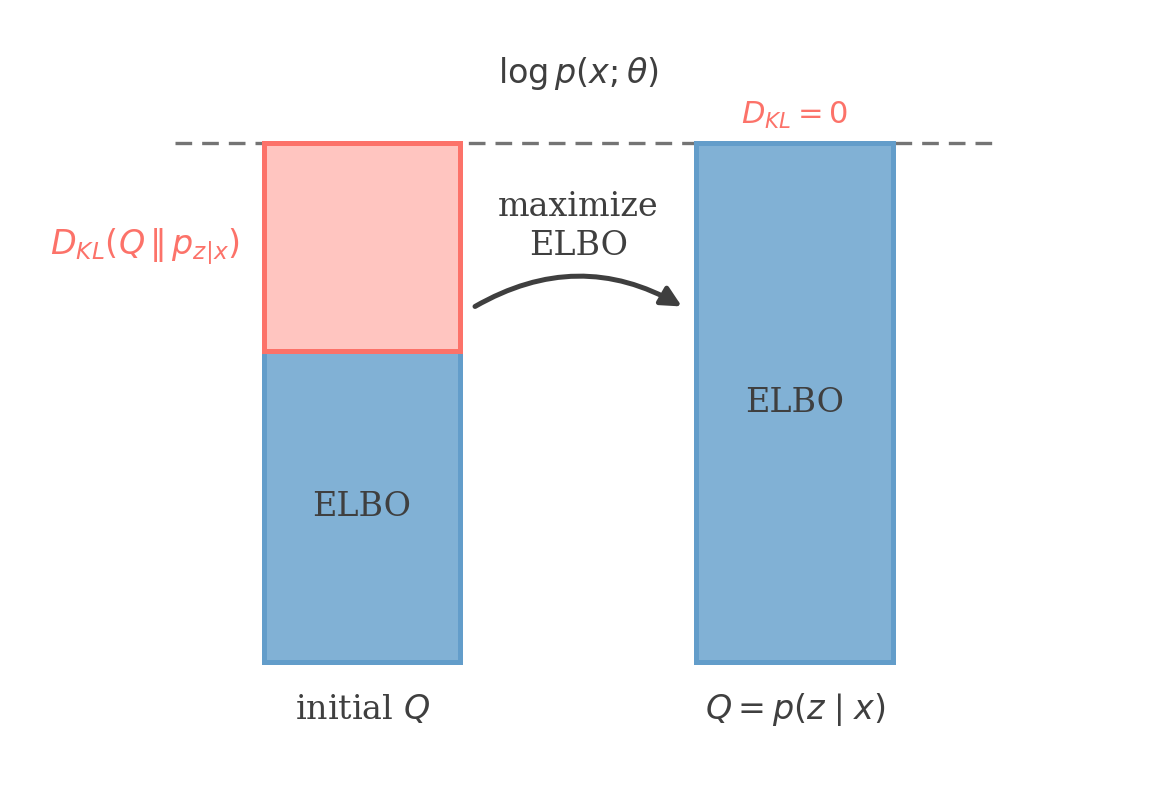
This shows us that ELBO is maximized for a given value of θ when the KL divergence between Q(z) and p(z∣x;θ) is minimized, which is when they are equal. This is exactly what we saw while deriving the algorithm above.
At a fixed θ, logp(x;θ) splits into the ELBO and the gap DKL(Q∥pz∣x); the E step sets Q=p(z∣x), closing the gap so the bound is tight.
See derivation
Please use a larger screen
This content is best viewed on a laptop or desktop device.