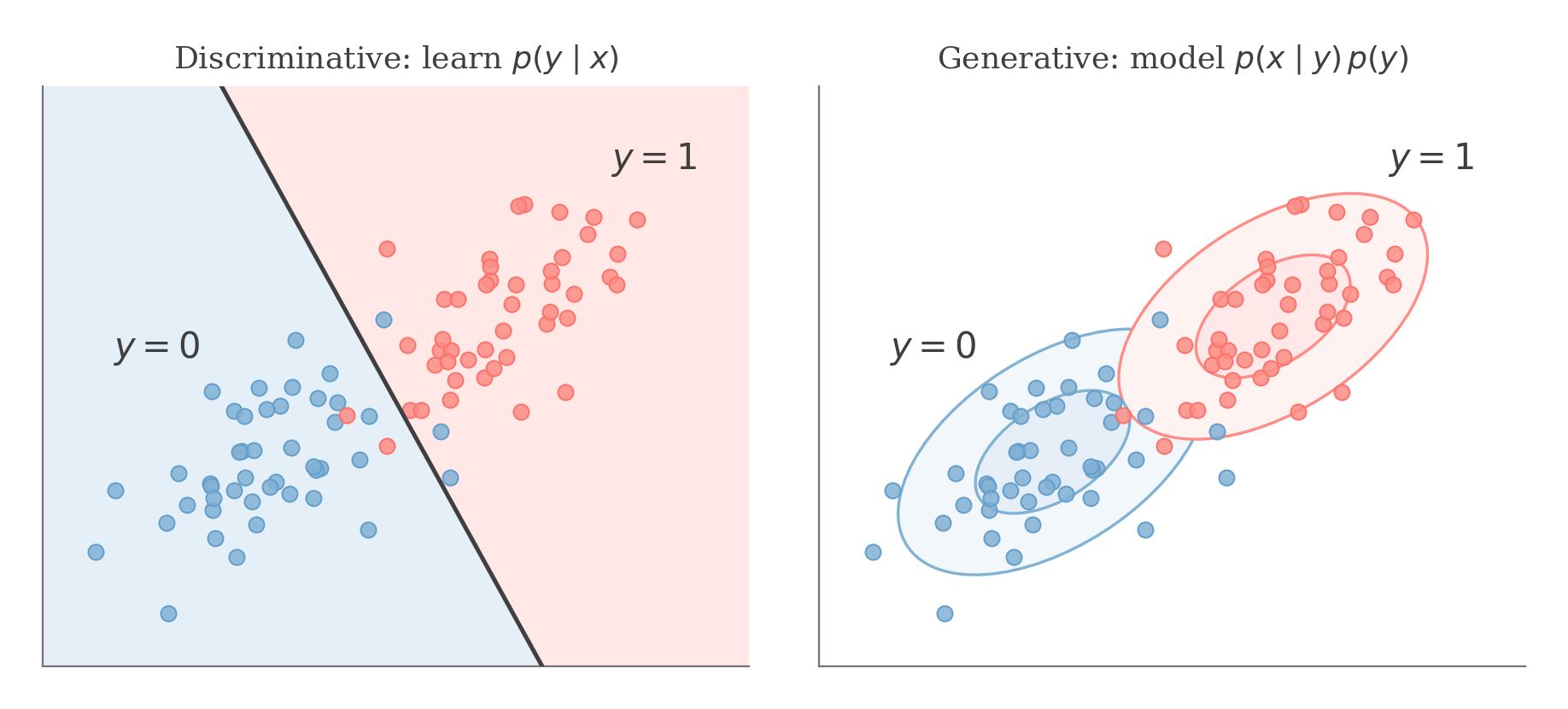
Generative Learning Algorithms Gaussian Discriminant Analysis
If we want to classify between cats and dogs, discriminative learning algorithms try to learn a hyperplane that separates the two classes directly. Generative learning algorithms, try to learn a model for what cats look like and a separate model to learn what dogs look like.
The discriminative model learns the boundary p ( y ∣ x ) p(y \mid x) p ( y ∣ x ) p ( x ∣ y ) p(x \mid y) p ( x ∣ y ) p ( y ) p(y) p ( y )
After modelling p ( x ∣ y ) p(x \mid y) p ( x ∣ y ) p ( y ) p(y) p ( y ) p ( y ∣ x ) p(y \mid x) p ( y ∣ x )
arg max y p ( y ∣ x ) = arg max y p ( x ∣ y ) p ( y ) p ( x ) \arg \max_y p(y \mid x) = \arg \max_y \, \frac{p(x \mid y) p(y)}{p(x)} arg y max p ( y ∣ x ) = arg y max p ( x ) p ( x ∣ y ) p ( y ) = arg max y p ( x ∣ y ) p ( y ) = \arg \max_y \, p(x \mid y) \, p(y) = arg y max p ( x ∣ y ) p ( y ) In Gaussian Discriminant Analysis (GDA), we assume that each of p ( x ∣ y ) p(x \mid y) p ( x ∣ y )
p ( y ) = ϕ y ( 1 − ϕ ) 1 − y p(y) = \phi^y (1 - \phi)^{1 - y} p ( y ) = ϕ y ( 1 − ϕ ) 1 − y p ( x ∣ y = 0 ) = 1 ( 2 π ) d / 2 ∣ Σ ∣ 1 / 2 exp ( − 1 2 ( x − μ 0 ) T Σ − 1 ( x − μ 0 ) ) p(x \mid y = 0) = \frac{1}{(2 \pi)^{d/2} |\Sigma|^{1/2}} \exp \left( -\frac{1}{2} (x - \mu_0)^T \Sigma^{-1} (x - \mu_0) \right) p ( x ∣ y = 0 ) = ( 2 π ) d /2 ∣Σ ∣ 1/2 1 exp ( − 2 1 ( x − μ 0 ) T Σ − 1 ( x − μ 0 ) ) p ( x ∣ y = 1 ) = 1 ( 2 π ) d / 2 ∣ Σ ∣ 1 / 2 exp ( − 1 2 ( x − μ 1 ) T Σ − 1 ( x − μ 1 ) ) p(x \mid y = 1) = \frac{1}{(2 \pi)^{d/2} |\Sigma|^{1/2}} \exp \left( -\frac{1}{2} (x - \mu_1)^T \Sigma^{-1} (x - \mu_1) \right) p ( x ∣ y = 1 ) = ( 2 π ) d /2 ∣Σ ∣ 1/2 1 exp ( − 2 1 ( x − μ 1 ) T Σ − 1 ( x − μ 1 ) ) The log-likelihood of the data is then given by:
ℓ ( ϕ , μ 0 , μ 1 , Σ ) = log ∏ i = 1 n p ( x ( i ) , y ( i ) ; ϕ , μ 0 , μ 1 , Σ ) \ell(\phi, \mu_0, \mu_1, \Sigma) = \log \prod_{i=1}^n \, p\left(x^{(i)}, y^{(i)}; \phi, \mu_0, \mu_1, \Sigma\right) ℓ ( ϕ , μ 0 , μ 1 , Σ ) = log i = 1 ∏ n p ( x ( i ) , y ( i ) ; ϕ , μ 0 , μ 1 , Σ ) By maximizing ℓ \ell ℓ
ϕ = 1 n ∑ i = 1 n 1 { y ( i ) = 1 } \phi = \frac{1}{n} \sum_{i=1}^n 1\left\{y^{(i)} = 1\right\} ϕ = n 1 i = 1 ∑ n 1 { y ( i ) = 1 } μ 0 = ∑ i = 1 n 1 { y ( i ) = 0 } x ( i ) ∑ i = 1 n 1 { y ( i ) = 0 } \mu_0 = \frac{\sum_{i=1}^n 1\left\{y^{(i)} = 0\right\} x^{(i)}}{\sum_{i=1}^n 1\left\{y^{(i)} = 0\right\}} μ 0 = ∑ i = 1 n 1 { y ( i ) = 0 } ∑ i = 1 n 1 { y ( i ) = 0 } x ( i ) μ 1 = ∑ i = 1 n 1 { y ( i ) = 1 } x ( i ) ∑ i = 1 n 1 { y ( i ) = 1 } \mu_1 = \frac{\sum_{i=1}^n 1\left\{y^{(i)} = 1\right\} x^{(i)}}{\sum_{i=1}^n 1\left\{y^{(i)} = 1\right\}} μ 1 = ∑ i = 1 n 1 { y ( i ) = 1 } ∑ i = 1 n 1 { y ( i ) = 1 } x ( i ) Σ = 1 n ∑ i = 1 n ( x ( i ) − μ y ( i ) ) ( x ( i ) − μ y ( i ) ) T \Sigma = \frac{1}{n} \sum_{i=1}^n \left(x^{(i)} - \mu_{y^{(i)}}\right) \left(x^{(i)} - \mu_{y^{(i)}}\right)^T Σ = n 1 i = 1 ∑ n ( x ( i ) − μ y ( i ) ) ( x ( i ) − μ y ( i ) ) T
Naive Bayes
When our feature vectors x x x
x ∈ { 0 , 1 } d x \in \{0, 1\}^d x ∈ { 0 , 1 } d We also make the assumption that x i x_i x i y y y
p ( x 1 , … , x d ∣ y ) = ∏ j = 1 d p ( x j ∣ y ) p(x_1, \ldots, x_d | y) = \prod_{j=1}^d p(x_j | y) p ( x 1 , … , x d ∣ y ) = j = 1 ∏ d p ( x j ∣ y ) We also assume that y y y 0 0 0 1 1 1
ℓ ( ϕ y , ϕ j ∣ y = 0 , ϕ j ∣ y = 1 ) = log ∏ i = 1 n p ( x ( i ) , y ( i ) ; ϕ y , ϕ j ∣ y = 0 , ϕ j ∣ y = 1 ) \ell(\phi_y, \phi_{j \mid y = 0}, \phi_{j \mid y = 1}) = \log \, \prod_{i=1}^n \, p \left( x^{(i)}, y^{(i)} ; \phi_y, \phi_{j \mid y = 0}, \phi_{j \mid y = 1} \right) ℓ ( ϕ y , ϕ j ∣ y = 0 , ϕ j ∣ y = 1 ) = log i = 1 ∏ n p ( x ( i ) , y ( i ) ; ϕ y , ϕ j ∣ y = 0 , ϕ j ∣ y = 1 ) = log ∏ i = 1 n ( ∏ j = 1 d p ( x j ( i ) ∣ y ( i ) ; ϕ j ∣ y = 0 , ϕ j ∣ y = 1 ) ) p ( y ( i ) ; ϕ y ) = \log \, \prod_{i=1}^n \, \left( \prod_{j=1}^d p\left(x_j^{(i)} \mid y^{(i)} ; \phi_{j \mid y = 0}, \phi_{j \mid y = 1}\right) \right) p\left(y^{(i)} ; \phi_y\right) = log i = 1 ∏ n ( j = 1 ∏ d p ( x j ( i ) ∣ y ( i ) ; ϕ j ∣ y = 0 , ϕ j ∣ y = 1 ) ) p ( y ( i ) ; ϕ y ) Maximizing our log likelihood function with respect to our parameters, we get:
ϕ j ∣ y = 1 = ∑ i = 1 n 1 { x j ( i ) = 1 ∧ y ( i ) = 1 } ∑ i = 1 n 1 { y ( i ) = 1 } \phi_{j \mid y = 1} = \frac{\sum_{i=1}^{n} 1\left\{x_j^{(i)} = 1 \land y^{(i)} = 1\right\}}{\sum_{i=1}^{n} 1\left\{y^{(i)} = 1\right\}} ϕ j ∣ y = 1 = ∑ i = 1 n 1 { y ( i ) = 1 } ∑ i = 1 n 1 { x j ( i ) = 1 ∧ y ( i ) = 1 } ϕ j ∣ y = 0 = ∑ i = 1 n 1 { x j ( i ) = 1 ∧ y ( i ) = 0 } ∑ i = 1 n 1 { y ( i ) = 0 } \phi_{j \mid y = 0} = \frac{\sum_{i=1}^{n} 1\left\{x_j^{(i)} = 1 \land y^{(i)} = 0\right\}}{\sum_{i=1}^{n} 1\left\{y^{(i)} = 0\right\}} ϕ j ∣ y = 0 = ∑ i = 1 n 1 { y ( i ) = 0 } ∑ i = 1 n 1 { x j ( i ) = 1 ∧ y ( i ) = 0 } ϕ y = 1 n ∑ i = 1 n 1 { y ( i ) = 1 } \phi_{y} = \frac{1}{n} \, \sum_{i=1}^{n} 1\left\{y^{(i)} = 1\right\} ϕ y = n 1 i = 1 ∑ n 1 { y ( i ) = 1 } Having fit all these parameters, to make a prediction on a new example, we simply calculate:
p ( y = 1 ∣ x ) = p ( x ∣ y = 1 ) p ( y = 1 ) p ( x ) p(y = 1|x) = \frac{p(x|y = 1)p(y = 1)}{p(x)} p ( y = 1∣ x ) = p ( x ) p ( x ∣ y = 1 ) p ( y = 1 ) p ( y = 1 ∣ x ) = ( ∏ j = 1 d p ( x j ∣ y = 1 ) ) p ( y = 1 ) ( ∏ j = 1 d p ( x j ∣ y = 1 ) ) p ( y = 1 ) + ( ∏ j = 1 d p ( x j ∣ y = 0 ) ) p ( y = 0 ) p(y = 1|x) = \frac{\left( \prod_{j=1}^{d} p(x_j|y = 1) \right) p(y = 1)}{\left( \prod_{j=1}^{d} p(x_j|y = 1) \right) p(y = 1) + \left( \prod_{j=1}^{d} p(x_j|y = 0) \right) p(y = 0)} p ( y = 1∣ x ) = ( ∏ j = 1 d p ( x j ∣ y = 1 ) ) p ( y = 1 ) + ( ∏ j = 1 d p ( x j ∣ y = 0 ) ) p ( y = 0 ) ( ∏ j = 1 d p ( x j ∣ y = 1 ) ) p ( y = 1 ) However, there is a problem with this approach. If any of the p ( x j ∣ y = 1 ) p(x_j|y = 1) p ( x j ∣ y = 1 ) x j x_j x j 1 1 1
As a workaround, we apply Laplace smoothing. Our parameters then become:
ϕ j ∣ y = 1 = 1 + ∑ i = 1 n 1 { x j ( i ) = 1 ∧ y ( i ) = 1 } 2 + ∑ i = 1 n 1 { y ( i ) = 1 } \phi_{j \mid y = 1} = \frac{1 + \sum_{i=1}^{n} 1\left\{x_j^{(i)} = 1 \land y^{(i)} = 1\right\}}{2 + \sum_{i=1}^{n} 1\left\{y^{(i)} = 1\right\}} ϕ j ∣ y = 1 = 2 + ∑ i = 1 n 1 { y ( i ) = 1 } 1 + ∑ i = 1 n 1 { x j ( i ) = 1 ∧ y ( i ) = 1 } ϕ j ∣ y = 0 = 1 + ∑ i = 1 n 1 { x j ( i ) = 1 ∧ y ( i ) = 0 } 2 + ∑ i = 1 n 1 { y ( i ) = 0 } \phi_{j \mid y = 0} = \frac{1 + \sum_{i=1}^{n} 1\left\{x_j^{(i)} = 1 \land y^{(i)} = 0\right\}}{2 + \sum_{i=1}^{n} 1\left\{y^{(i)} = 0\right\}} ϕ j ∣ y = 0 = 2 + ∑ i = 1 n 1 { y ( i ) = 0 } 1 + ∑ i = 1 n 1 { x j ( i ) = 1 ∧ y ( i ) = 0 } ϕ y = 1 n ∑ i = 1 n 1 { y ( i ) = 1 } \phi_y = \frac{1}{n} \, \sum_{i=1}^{n} 1\left\{y^{(i)} = 1\right\} ϕ y = n 1 i = 1 ∑ n 1 { y ( i ) = 1 }