Learning Theory
Bias-Variance Tradeoff
Let be our set of training examples that are related using the following equation:
where is the best possible classifier that maps the relationship between and , and is the noise in the th example.
Also, let be our best fit model for the dataset . The Mean Squared Error (MSE) can be written as:
Also, let be the "average model" - the model obtained by drawing an infinite number of datasets, training on them, and averaging their predictions on .
Then, the Mean Squared Error can be further broken down into 3 components:
The first part is the unavoidable error. It is the noise in the data that cannot be explained by any model, regardless of its complexity.
The bias is the error introduced by the "expressivity handicap" of our classifier. This error occurs because of underfitting.
The variance is the error that measures how much the model's predictions would change if it were trained on a different dataset.
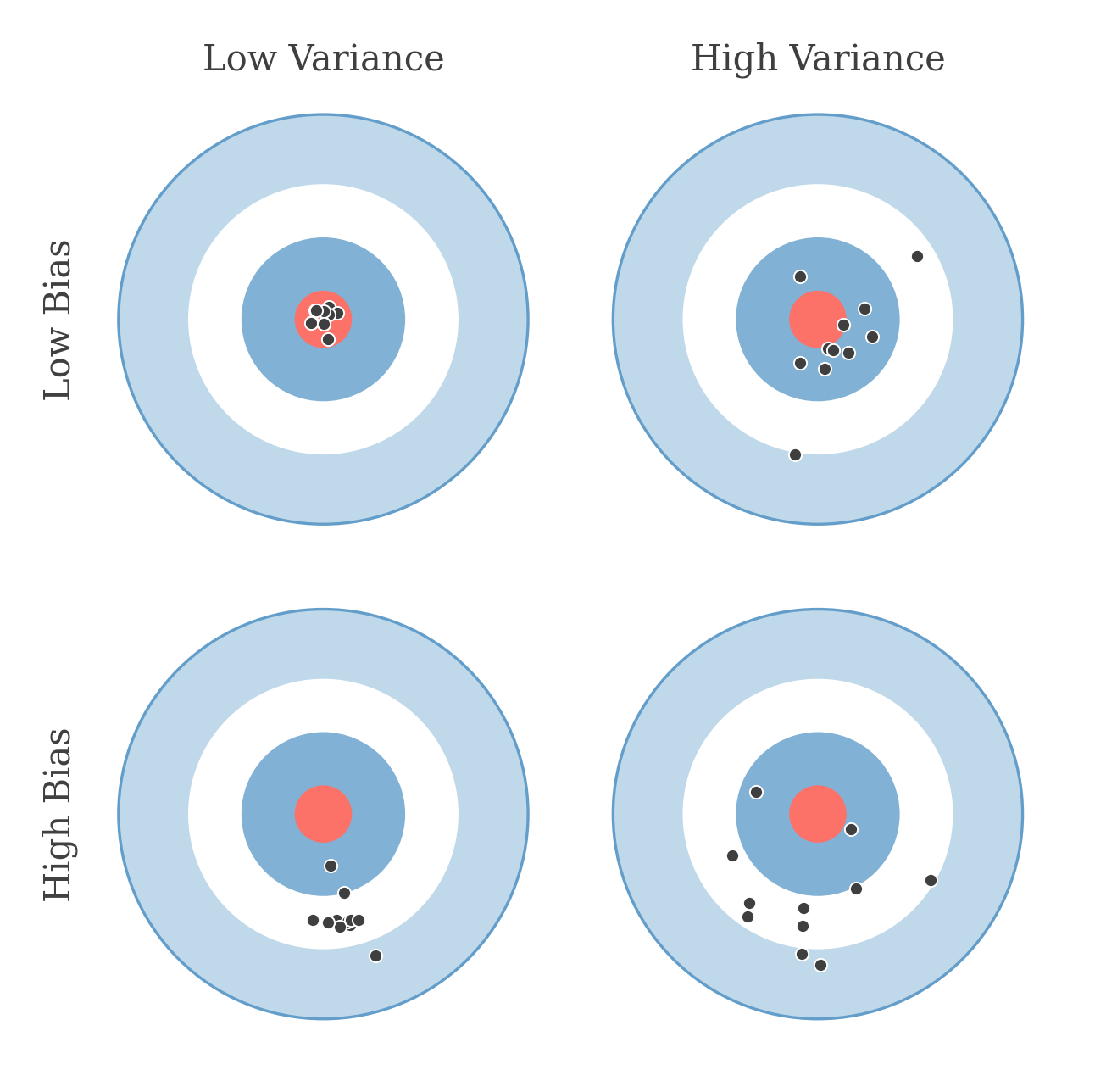
Each shot is a model fit on a different dataset: bias is how far the cluster sits from the bullseye , while variance is how spread out the shots are.
The Bias-Variance tradeoff tells us that as we increase the number of parameters in our neural network, the test error will decrease because the bias is decreasing. However, after a certain point the variance starts increasing faster than the bias is decreasing and therefore, the test error will start to increase.
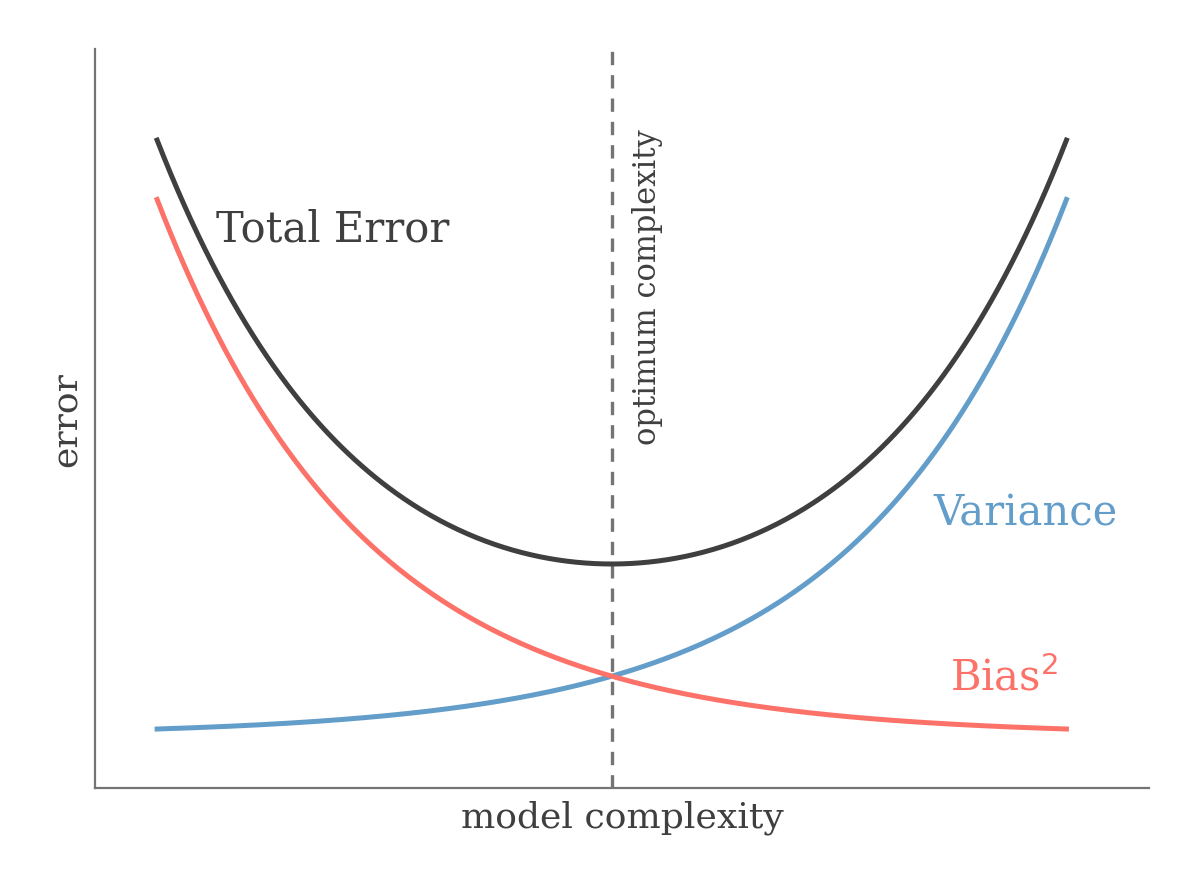
As model complexity grows, falls and variance rises; their sum — the total error — is minimized at the intermediate optimum where the two curves cross.
In reality, however, we see a double descent phenomenon wherein the test error starts to decrease again at the point where the number of parameters are approximately equal to the number of training examples . This is called the over-parameterization regime.
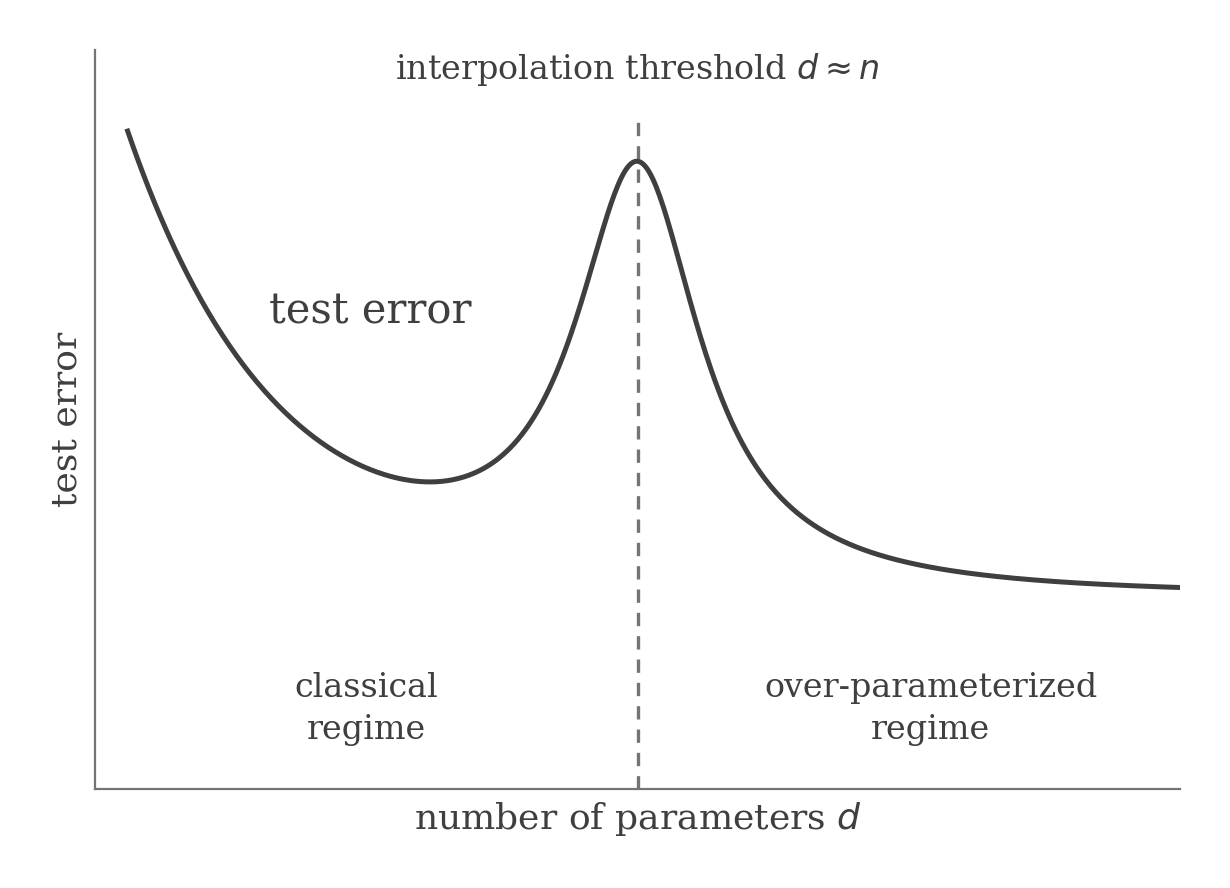
Past the interpolation threshold , the test error falls a second time, dropping below the classical minimum in the over-parameterized regime.
Complexity Bounds
For any hypothesis , the true error is given by:
However, since we have no way of determining the underlying probability distribution , we cannot determine the true error of the hypothesis. Instead, we estimate the empirical error of the hypothesis over our training examples.
Let be the set of all possible hypotheses that we are considering. To find the hypothesis that minimizes the empirical error over our training set, we find:
Hoeffding inequality states that for independent random variables drawn from a Bernoulli distribution i.e. and , the following inequality holds:
where and is some constant greater than 0.
Imagine a biased coin that comes up heads with a probability of . We toss this coin times and record the average number of times we got heads. We denote this average by .
The probability that "the true probability of getting heads is away from our estimated probability by a difference more than " is denoted by . This is always less than or equal to .
Using Hoeffding inequality, we note that the true error and the estimated empirical error of our selected hypothesis follow the following inequality:
Now we want to find an inequality for our entire set of hypotheses . We see that the following inequality holds:
We call this the uniform convergence result.
This means that as increases, the probability of the true error being close to the empirical error is bounded by a bigger value. Whereas, as we increase the number of hypotheses in our set, this probability is actually bounded by a smaller value.
In the context of learning, we can say that the more complex our model, the lower our probability of minimizing the empirical error. And the more the number of training examples, the higher our probability of minimizing the empirical error.
Now let
We see that if we want the probability of "the true error being within to the empirical error for all hypotheses under our consideration" to be at least , our needs to be at least as large as:
Similarly, we can also see that given and , the difference between the true error and the empirical error (for all hypotheses in our set) will always be less than:
Next, in our set of hypotheses , let be the hypothesis that minimizes the true error and be the hypothesis that minimizes our empirical error.
Using our uniform convergence assumption, we can see that:
With a probability of , the true error of our selected hypothesis is less than or equal to the true error of the best hypothesis + some term that depends on the number of hypotheses and the number of training examples.
The first term on the right can be thought of as the bias. And the second term can be thought of as the variance. We see that as we increase k, the first term either stays the same or potentially decreases. Whereas, the second term increases.
This is similar to what we saw in the Bias-Variance tradeoff. As we increase the complexity of our model, variance increases and the potential for our model to overfit also increases.
Please use a larger screen
This content is best viewed on a laptop or desktop device.