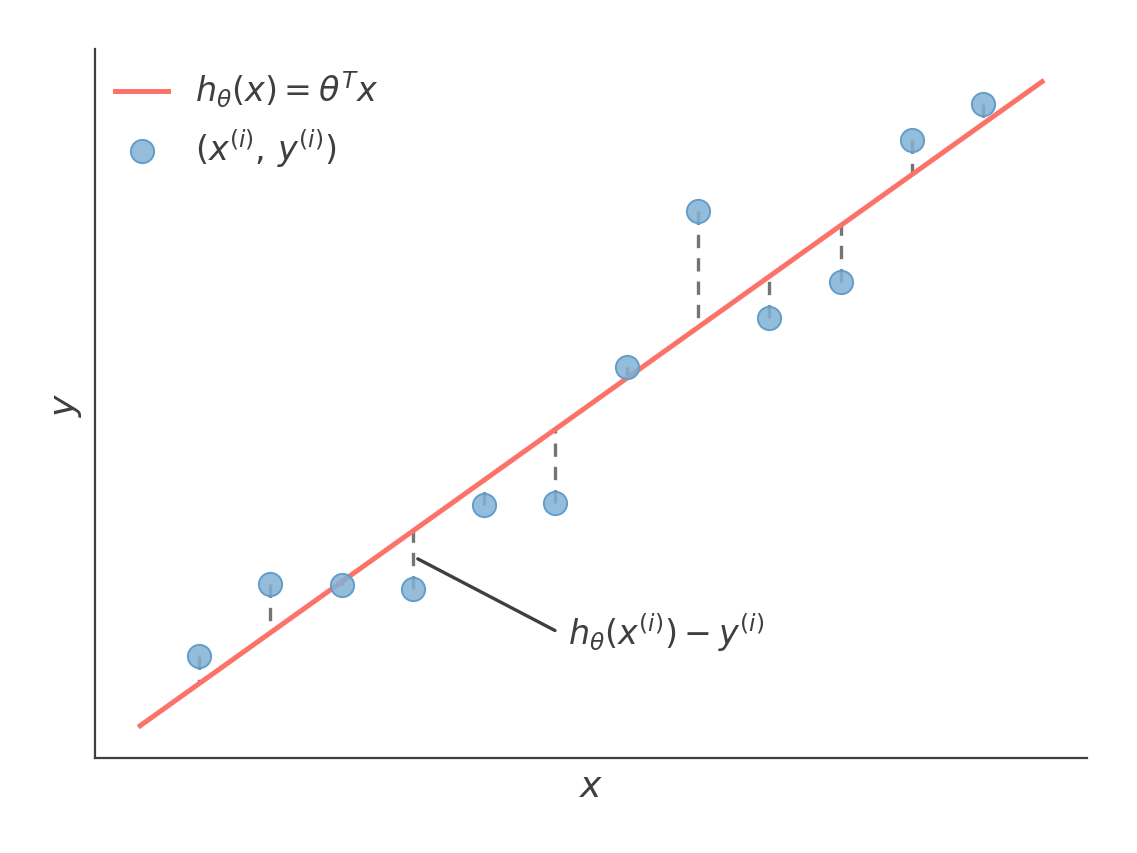
We define a function hθ(x) to model the d features in each x(i) as:
hθ(x)=j=1∑dθjxj(i)=θTx
For n training examples, we also define a cost function that we want to minimize:
J(θ)=21i=1∑n(hθ(x(i))−y(i))2
The cost function measures the squared vertical residuals between each training label and the fitted line.
Taking the derivative with respect to any θj we get:
∂θj∂J(θ)=i=1∑n[hθ(x(i))−y(i)]xj(i)
See derivation
With this derivative, we can now use gradient descent to take small steps towards the optimal θ with the following update rule:
θj←θj+α(y(i)−hθ(x(i)))xj(i)
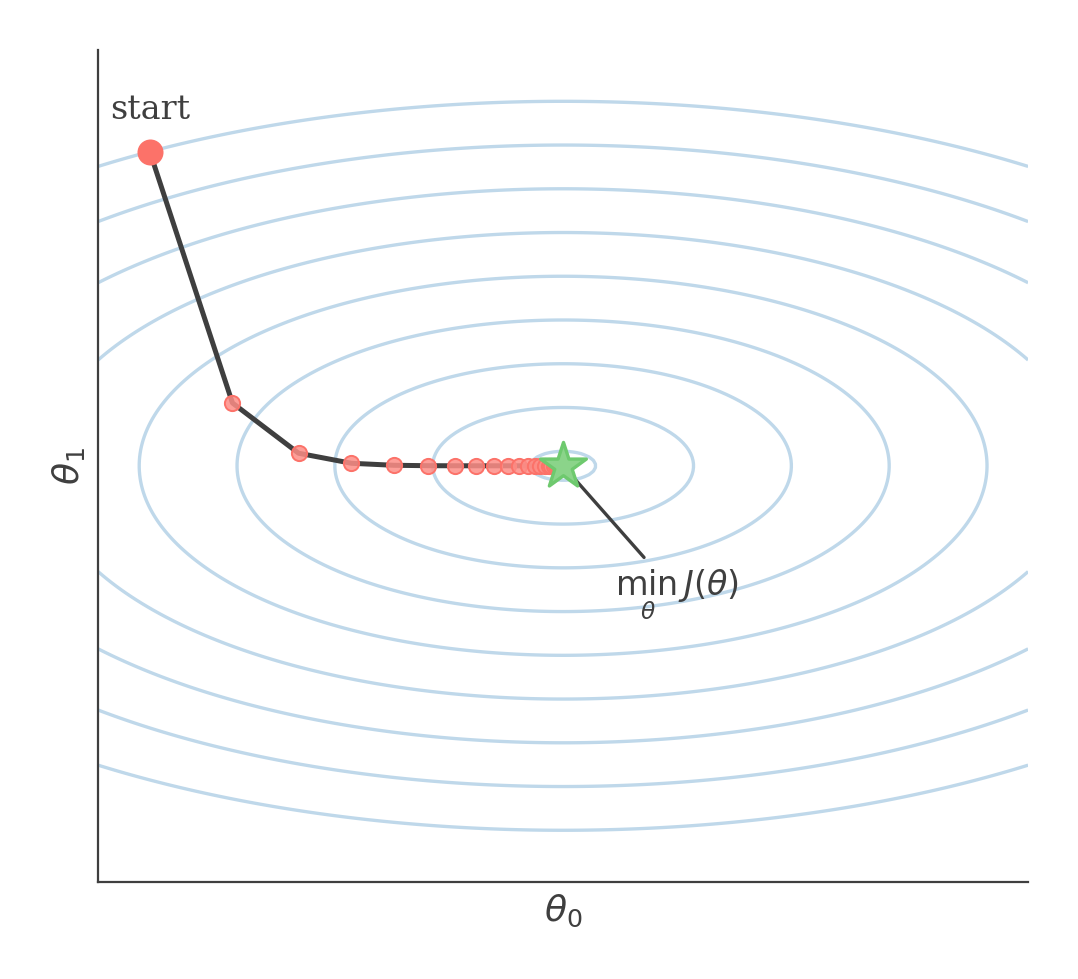
Gradient descent updates θ by moving downhill along the contours of J(θ) until it reaches the minimum.
Repeat until convergence {For i=1 to n,{For j=1 to d,{θj←θj+α(y(i)−hθ(x(i)))xj(i)}}}
Closed Form Solution
Let X be a matrix that contains each (x(i))T in its rows and has a size of n by d+1 where d is the number of features in x(i) and +1 is for the intercept term.
Also, y is an n dimensional vector that contains the labels for each training example. And θ is a d dimensional vector that contains the weights for each feature.
Now, since hθ(x)=(x(i))Tθ, we can rewrite this in matrix-vector form as hθ(x)=Xθ
With these, we can now rewrite J(θ) using the fact that zTz=∑izi2
Finally, to minimize J(θ), we find its derivative with respect to θ, set it equal to 0 and simplify to see that θ is minimized when,
θ=(XTX)−1XTy
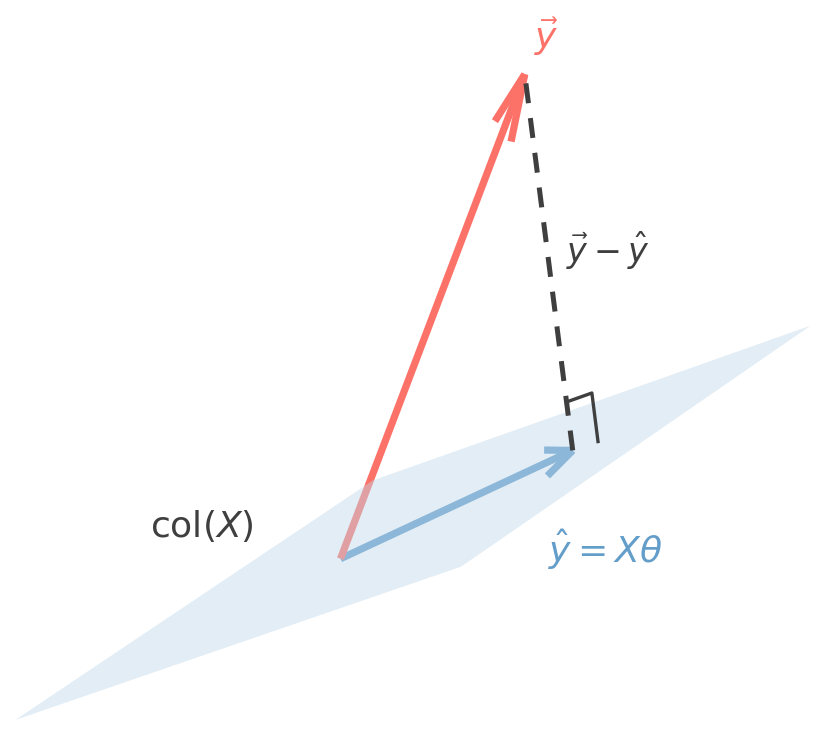
The closed-form solution chooses the prediction vector y^=Xθ that is closest to y inside the column space of X.
See derivation
Probabilistic Interpretation
We assume that y(i) with ϵ(i) as the noise in the ith example such that ϵ(i)∼N(0,σ2)
y(i)=θTx(i)+ϵ(i)
This can be rewritten as ϵ(i)=θTx(i)−y(i). Now, since ϵ(i)∼N(0,σ2), hence (y(i)−θTx(i))∼N(0,σ2).
Finally, if we are given x(i), then y(i)∣x(i) will also follow N(0,σ2) shifted by θTx(i).
P(y(i)∣x(i);θ)∼N(θTx(i),σ2)
To find the maximum likelihood estimate of θ, we need to maximize:
L(θ)=L(θ;X,Y)=i=1∏np(y(i)∣x(i);θ)
Since log is a monotonically increasing function, we can maximize the following instead:
ℓ(θ)=logi=1∏np(y(i)∣x(i);θ)
Solving this we see that maximizing ℓ(θ) is equivalent to minimizing:
−21i=1∑n(y(i)−θTx(i))2
Notice that the function that we need to minimize does not depend on σ, which means that we don't need to know the variance of our noise to be able to maximize our likelihood.
See derivation
Please use a larger screen
This content is best viewed on a laptop or desktop device.