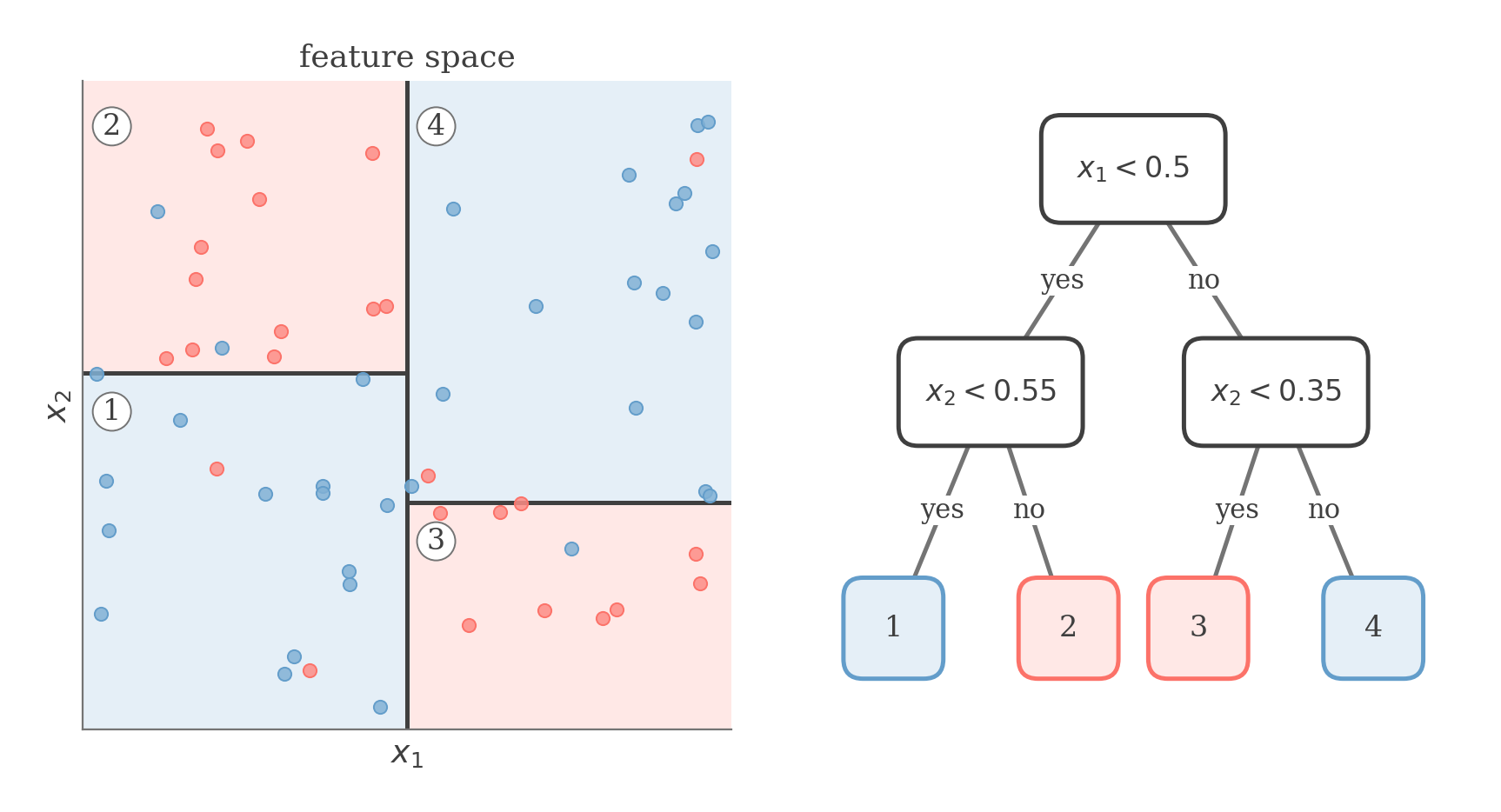
In the K-means Algorithm, we made an inherent assumption that data points of various classes are not randomly sprinkled across the space, but instead appear in clusters of more or less homogeneous space.
Decision trees exploit this very assumption to build a tree structure that recursively divides the feature space into regions with similar labels.
Each split is an axis-aligned cut; together they carve the feature space into rectangular leaves, and each leaf of the tree corresponds to one shaded region on the left.
For this purpose, we use the concept of purity. We want to split the data at each node such that the resulting subsets are as pure as possible.
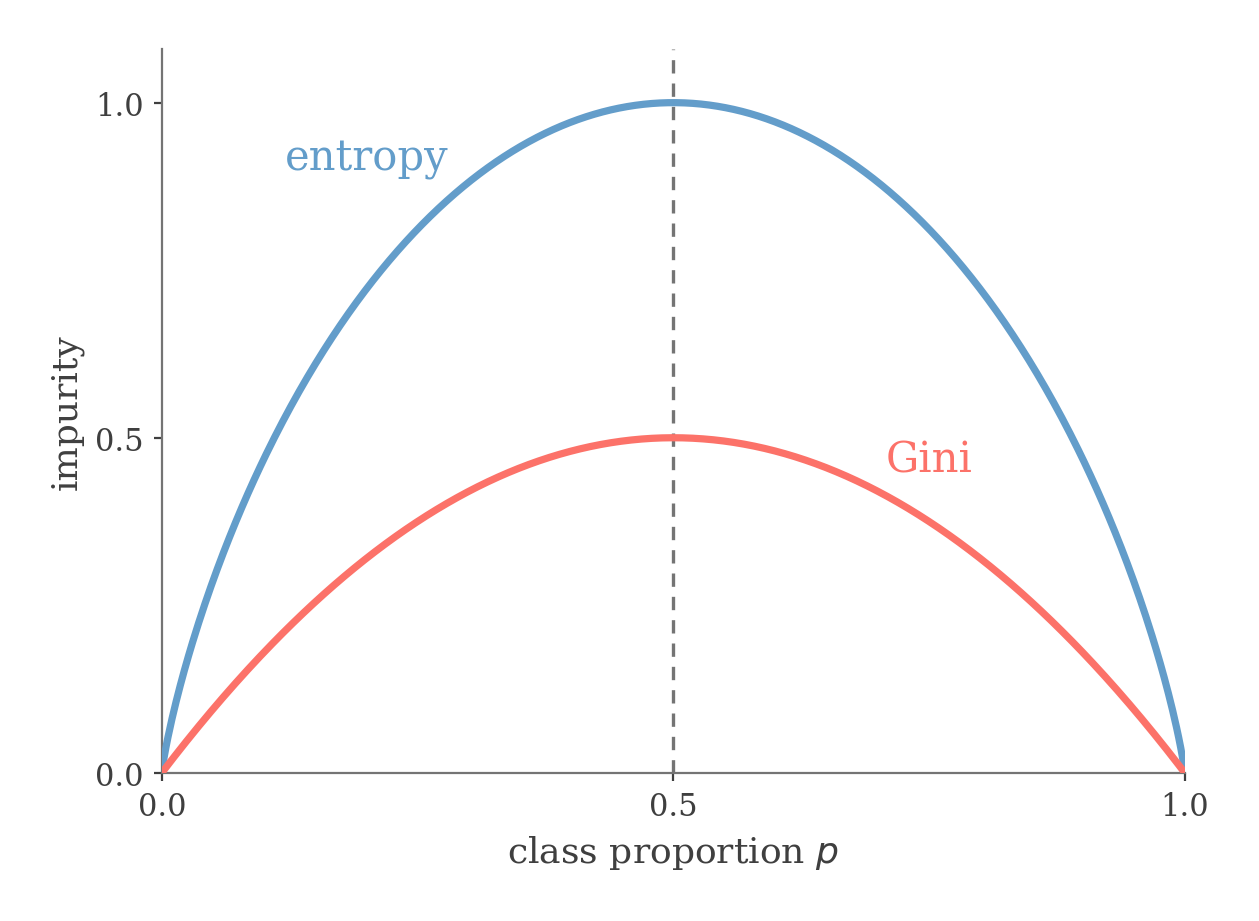
Two common impurity measures are Gini impurity and entropy.
Let S={(x(1),y(1)),…,(x(n),y(n))} be a set of training examples where y(i)∈{1,…,c} for c classes. Then we can define the probability of any class k as:
pk=∣S∣∣Sk∣
The Gini impurity of a leaf S is given by:
G(S)=k=1∑cpk(1−pk)
And for a split S→SL,SR, the Gini impurity is given by:
G(S)=∣S∣∣SL∣⋅G(SL)+∣S∣∣SR∣⋅G(SR)
Similarly, the entropy of a leaf S is given by:
H(S)=−k=1∑cpklogpk
And for a split S→SL,SR, the entropy impurity is given by:
H(S)=∣S∣∣SL∣⋅H(SL)+∣S∣∣SR∣⋅H(SR)
Also, note that the worst case for our probabilities is if they follow a uniform distribution and pk=c1 for each k because this would mean that each leaf is equally likely and our predictions are as good as random guessing.
Both Gini and entropy vanish for a pure node and are maximal at p=21, so a split is rewarded for pushing the class proportions toward 0 or 1.
If we let this distribution be q then we see that minimizing the entropy is equivalent to maximizing the KL-divergence DKL(p∣∣q).
However, building a maximally compact tree with only pure leaves for any data set is an NP-hard problem. Therefore, we use a greedy approach instead.
One example of this is the ID3 algorithm. In this algorithm, we start at the root node and at each step select the feature xj that best separates the data and minimizes the impurity. We then recurse on the left and right subsets defined by this split until we can no longer split the data.
A problem with this approach is that the ID3 algorithm stops splitting if a single split doesn't reduce impurity, even though a combination of splits might.
Another example of the greedy approach is the CART (Classification and Regression Trees) algorithm. CART can handle both classification and regression tasks. For regression tasks, the cost function is the squared error and for classification tasks it is the Gini impurity or entropy.
Bagging
From Bias-Variance Tradeoff, we know that the Mean Squared Error (MSE) between the best possible classifier and our classifier can be broken down.
The variance term indicates how much the model's predictions would change if it were trained on a different dataset.
If we let Di be the ith dataset, then for n datasets, we can define the average model as the ensemble average:
h^(x)=n1j=1∑nhDj(x)
As n→∞, according to the Law of Large Numbers, our average model h^(x) will converge to havg(x).
This means that if we have infinite datasets and we train our classifiers on each data set and then take an average, we can reduce the variance to 0.
However, we do not have infinite datasets, we only have one. Therefore, we use Bootstrapping instead. We sample n datasets with replacement from our original dataset D.
Note that doing this means that our datasets are not independent and identically distributed and according to the Law of Large Numbers is no longer guaranteed. In practice, however, doing this still helps us reduce the variance to some extent.
Next, to find the unbiased estimate of the test error, we need to find the out-of-bag (OOB) error.
Let Si be the set of all sampled data sets that do not contain the ith example. Then our prediction for the ith example is given by:
h~i(x)=∣Si∣1j∈Si∑hj(x)
Then the out-of-bag error is given by:
ϵoob=n1i=1∑∣D∣loss(h~i(x(i)),y(i))
Random Forest is an example of Bagging. In Random Forest, each decision tree is trained on a bootstrapped sample of the data, and only a random subset of k features are considered for splitting at each node. Each tree is grown to its full depth, and then an ensemble average is used to make predictions.
Usually k=d where d is the total number of features in each example.
Boosting
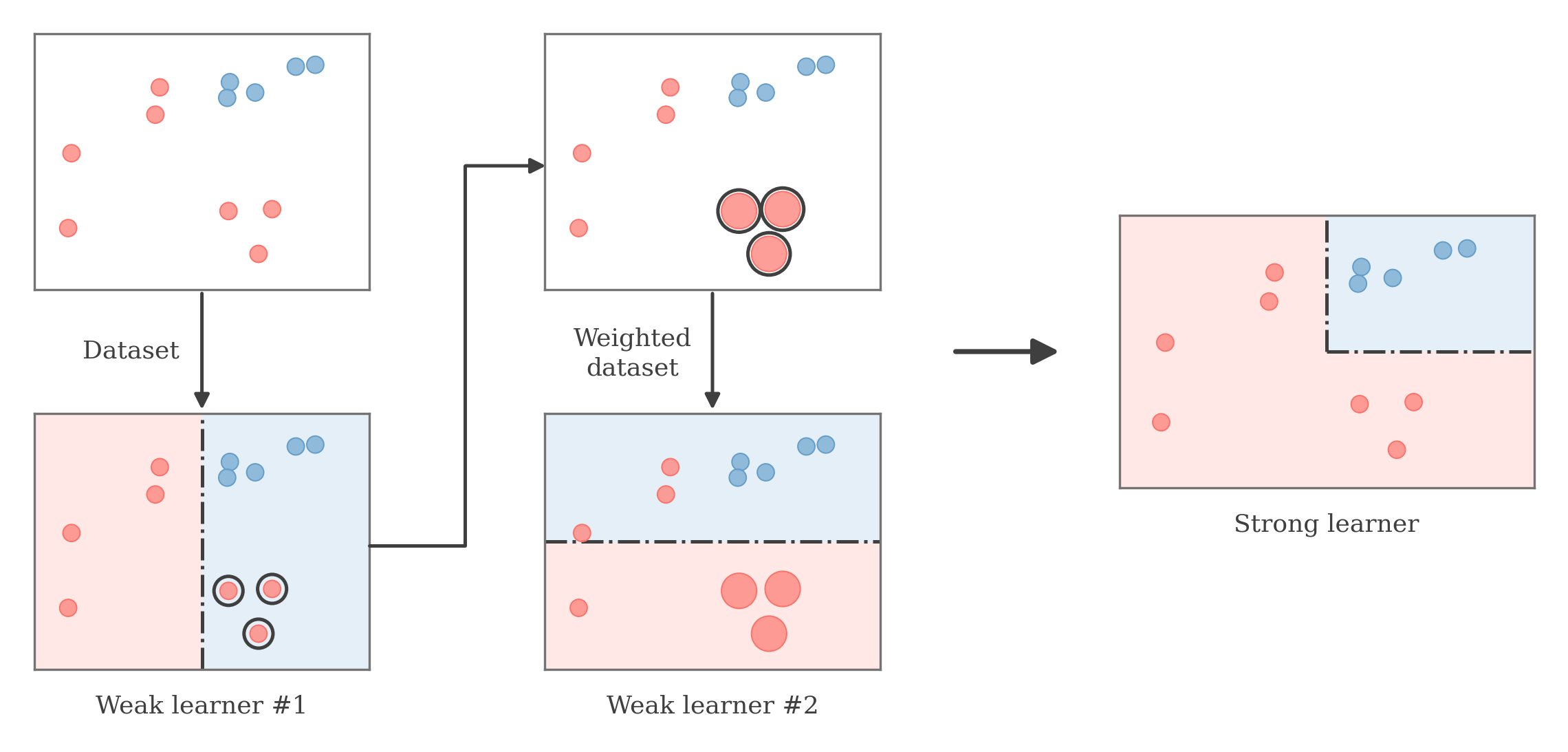
Boosting uses an ensemble of weak learners, added in an iterative manner, to form a strong learner with low bias.
In each iteration, we find a classifier h from our set of classifiers H that minimizes the loss function ℓ.
ht+1=argh∈Hminℓ(Ht+αh)
Our ensemble classifier can thus be written as:
Ht(x)=i=1∑tαihi(x)
To find the classifier that minimizes the loss function at any given step, we can use gradient descent in function space.
ht+1=argh∈Hminℓ(Ht+αh)
This can be rewritten as:
ht+1=argh∈Hmin[i=1∑n∂Ht(x(i))∂ℓ⋅h(x(i))]
If ℓ is the square loss function, we can further rewrite this as:
ht+1=argh∈Hmin[i=1∑n(Ht(x(i))−y(i))⋅h(x(i))]
See derivation
Note that y(i)−Ht(x(i)) represents the vector from Ht(x(i)) to y(i). Therefore, any ht+1 that moves us closer to y(i) will have a high dot product with this vector.
From this it follows that such a vector will have a negative dot product with Ht(x(i))−y(i).
Therefore, we want to select ht+1 such that:
[Ht(x(i))−y(i)]⋅ht+1(x(i))<0
We can use this observation to write a Generic Boosting algorithm.
Repeat {For each i, let r(i)←∂H(x(i))∂ℓh←argh∈Hmini=1∑nr(i)h(x(i))temp←i=1∑nr(i)h(x(i))if (temp<0) then {H←H+α⋅h} else {return H}}
AdaBoost
AdaBoost is a boosting algorithm that is used for classification tasks.
Each round fits a weak learner, then upweights the examples it misclassifies so the next learner focuses on them; the weighted combination of the weak learners forms the strong learner.
We assume that y(i)∈{−1,1} and h(x)∈{−1,1}.
We also use an exponential loss function:
ℓ(H)=e−y(i)⋅H(x(i))
The gradient of this loss function is given by:
∂H(x(i))∂ℓ=−y(i)⋅e−y(i)⋅H(x(i))
Using this gradient, we can see that the best classifier ht is the one that minimizes the loss function can be written as a weighted misclassification error:
In AdaBoost, we can also find the optimal step size by minimizing the loss function with respect to α.
α=argαminℓ(Ht+αh)
Doing so, we find a closed form solution for the optimal step size in terms of the weighted classification error.
α=21ln(ϵ1−ϵ)ϵ=i=1∑n1{y(i)=h(x(i))}⋅w(i)
See derivation
After taking each step, we need to recompute our weights and renormalize them so that they sum to one.
The update rules for the unnormalized weights and normalization constant are given by:
w^(i)←w^(i)⋅e−αy(i)h(x(i))z←z∗2ϵ(1−ϵ)
Putting these together, we get the following update rule for the normalized weights:
w(i)←w(i)⋅2ϵ(1−ϵ)e−αy(i)h(x(i))
See derivation
Note that when ϵ=21, that means that our weighted misclassification error is equal to 50%. This means that our new classifier ht+1 is no better than random guessing. Therefore, we only want to add a new classifier to our current ensemble if ϵ<21.
For each i, let w(i)←n1Repeat {h←argh∈Hmini=1∑n1{y(i)=h(x(i))}⋅w(i)ϵ←i=1∑n1{y(i)=h(x(i))}⋅w(i)if (ϵ<0.5) then {α←21ln(ϵ1−ϵ)H←H+α⋅hFor each i, let w(i)←w(i)⋅2ϵ(1−ϵ)e−αy(i)ht+1(x(i))}else {return H}}
Please use a larger screen
This content is best viewed on a laptop or desktop device.