Suppose that we are given a training set x(1),…,x(n) and we wish to model the data by specifying a joint distribution p(x(i),z(i)) where z(i)∼Multinomial(ϕ) is a latent variable where p(z(i)=j)=ϕj and ∑j=1kϕj=1 where k is the number of values that z(i) can take.
Moreover, we assume that x(i)∣z(i)=j∼N(μj,Σj). Gaussian mixture models are similar to the K-means Algorithm except that we allow for overlapping clusters and each cluster follows a Gaussian distribution.
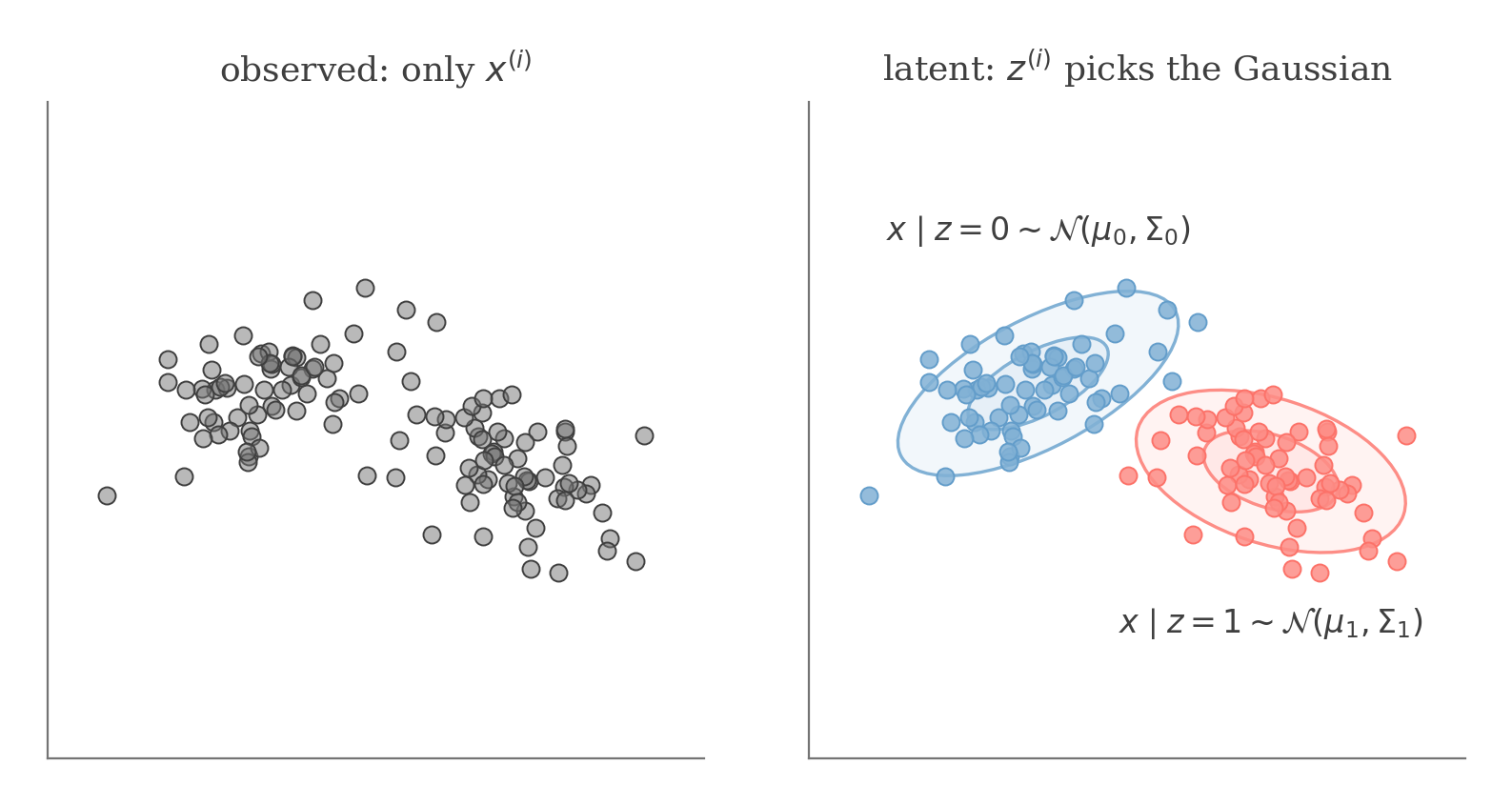
All we observe is the unlabeled cloud x(i) (left). The model explains it with a hidden z(i) that picks one of two Gaussians, each generating its points as x∣z=j∼N(μj,Σj) (right). If we knew the z(i)'s, fitting each Gaussian would be easy.
To maximize the log likelihood, we need to maximize:
The random variables z(i)'s indicate which of the k Gaussians each x(i) had come from. Note that if we knew what the z(i)'s were, the maximum likelihood problem would have been easy and almost similar to that of Gaussian Discriminant Analysis.
Since there is no way for us to take the derivative of the above equation and find a closed form solution, we need to use the Expectation Maximization Algorithm instead.
In the E step, for all values of i and j, we find p(z(i)=j∣x(i);ϕ,μ,Σ) using the current parameters and Bayes' rule:
When we plug in the equations for the gaussian distribution, this takes a form very similar to the softmax function. So in the E step, we find our estimated probability distribution for what value z(i) should take for each x(i).
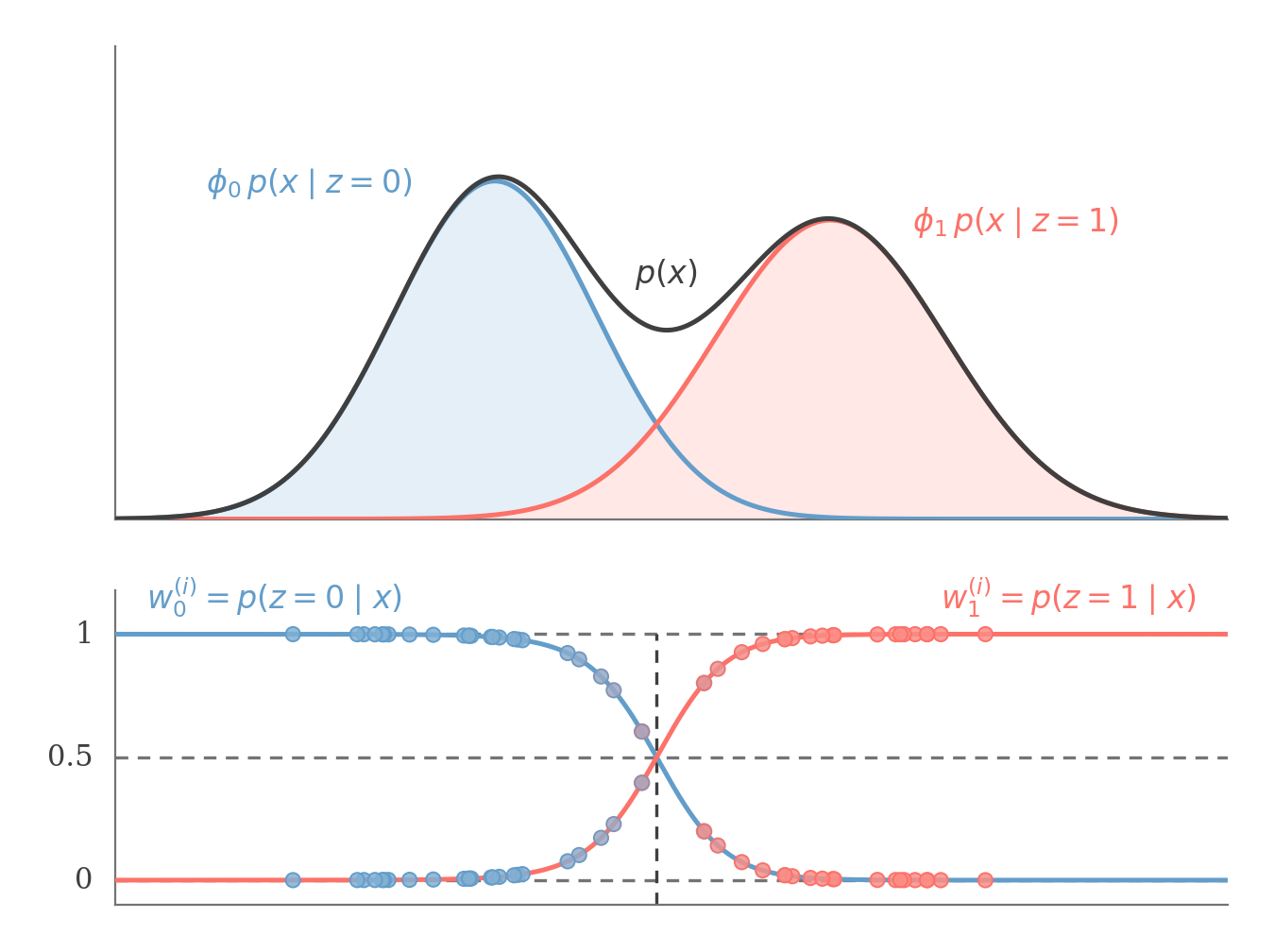
The mixture p(x) is the sum of the weighted components ϕjp(x∣z=j) (top). The E step assigns each point softly: the responsibilities wj(i)=p(z=j∣x(i)) move smoothly between 0 and 1 and sum to one (bottom), unlike the hard assignment of k-means.
See derivation
Now for the M step, for each j, we find the values of our parameters that maximize our new ELBO with:
When we take the derivative of the above equation with respect to each of our parameters ϕ,μ,Σ, and set it equal to 0, we get our update equations for each of the parameters:
Repeat until convergence {(E-step) For each i and j, set {wj(i)←p(z(i)=j∣x(i);ϕ,μ,Σ).}(M-step) For each j, set {ϕj←n1i=1∑nwj(i)μj←∑i=1nwj(i)∑i=1nwj(i)x(i)Σj←∑i=1nwj(i)∑i=1nwj(i)(x(i)−μj)(x(i)−μj)T}}
In the E step, we estimate the probability of each z(i) given x(i) using the current parameters ϕ,μ,Σ.
In the M step, we update the value of our parameters to maximize the ELBO for which it is equal to p(x;μ,Σ) for our current values of ϕ,μ,Σ.
Please use a larger screen
This content is best viewed on a laptop or desktop device.